What is a neural network?
Explore neural networks: components, tasks, and structure. Learn about neurons, layers, and data requirements for effective training in classification and regression.

Classical Neural Networks
Classical neural networks are inspired by the structure of the human brain. They consist of interconnected nodes called neurons, which are arranged in layers. The simplest form is the feedforward neural network, where information flows in a single direction—from input to output.
Introduction to Components
To understand neural networks, we need to examine their components: neurons (processing units), weights and edges (signal pathways), and layers (neuron organization). By understanding these components, we can better grasp how neural networks process information.
Neurons
Neurons in a neural network process information. They connect to other neurons via edges, receiving input values from multiple neurons and sending output values. Each neuron calculates a weighted sum of its inputs and applies an activation function, such as ReLU or sigmoid, to produce an output. This output is then passed to the next layer of neurons, enabling the network to make decisions.
Weights and Edges
Edges are the connections between neurons, and each edge has an associated weight. These weights adjust the strength of the signals transmitted, influencing the network’s output. By adjusting weights through training, the network learns and improves its predictions.
Standard Tasks for a Classical Neural Network
Neural networks typically perform two types of tasks: classification and regression.
Classification: A classification task involves sorting data into categories. The network analyzes the input and decides which category it belongs to. For instance, in natural language processing, a neural network can read an email and determine if it’s spam or not. The categories in this case are “spam” and “not spam.” The network learns from examples, enabling it to make accurate decisions with new emails.
Regression: A regression task involves predicting a numerical value based on input data. For example, in natural language processing, a neural network can analyze customer reviews and predict the average rating, such as 4.2 stars out of 5. Instead of sorting into categories, it provides a specific value. The network learns from past data to make accurate predictions for new inputs.
Layers in Neural Networks
Neural networks are structured into layers:
-
Input Layer: The input layer receives raw data, with each node representing a feature. For instance, in image recognition, each node might represent a pixel’s color value. In text processing, words are converted into numerical features using techniques like word embedding.
-
Hidden Layer: In the hidden layer, each neuron is often fully connected to all neurons in the previous layer. This allows for complex transformations of the input data through multiple layers. The hidden layer transforms the input data into a form that the output layer can use. Multiple hidden layers enable the learning of complex patterns.
-
Output Layer: Each node in the output layer produces the final output, which could be a classification, prediction, or other result depending on the network’s purpose. For classification tasks, the output node corresponding to the chosen category has the highest value. For regression tasks, the output node provides the predicted numerical value.
Example of Features in Sentiment Analysis
Consider a sentiment analysis model aiming to predict whether a given text is positive or negative. Here are some example features that might be used:
- Word Count: The total number of words in the text.
- Average Word Length: The average length of words in the text.
- Positive Words: The number of positive words in the text.
- Negative Words: The number of negative words in the text.
- Contains “excellent”: A binary feature indicating whether the text contains the word “excellent”.
- Contains “terrible”: A binary feature indicating whether the text contains the word “terrible”.
How Features are Used in a Neural Network
- Input Layer:
- Each feature corresponds to a node in the input layer of the neural network. For instance, if there are 6 features, the input layer will have 6 nodes.
- Hidden Layers:
- The input features are processed through one or more hidden layers. Each node in these layers applies a weighted sum and an activation function to the input features.
- Output Layer:
- The final processed information is passed to the output layer, which generates the prediction, such as the predicted sentiment.
Example Neural Network Structure
For the sentiment analysis example, a simple neural network might have the following structure:
- Input Layer: 6 nodes (one for each feature: Word Count, Avg Word Length, Positive Words, Negative Words, Contains “excellent”, Contains “terrible”)
- Hidden Layer 1: 10 nodes (an arbitrary number for processing)
- Hidden Layer 2: 5 nodes (another arbitrary number for further processing)
- Output Layer: 1 node (to predict the sentiment)
To better visualize this neural network structure, let’s look at a diagram that illustrates how these layers are connected:
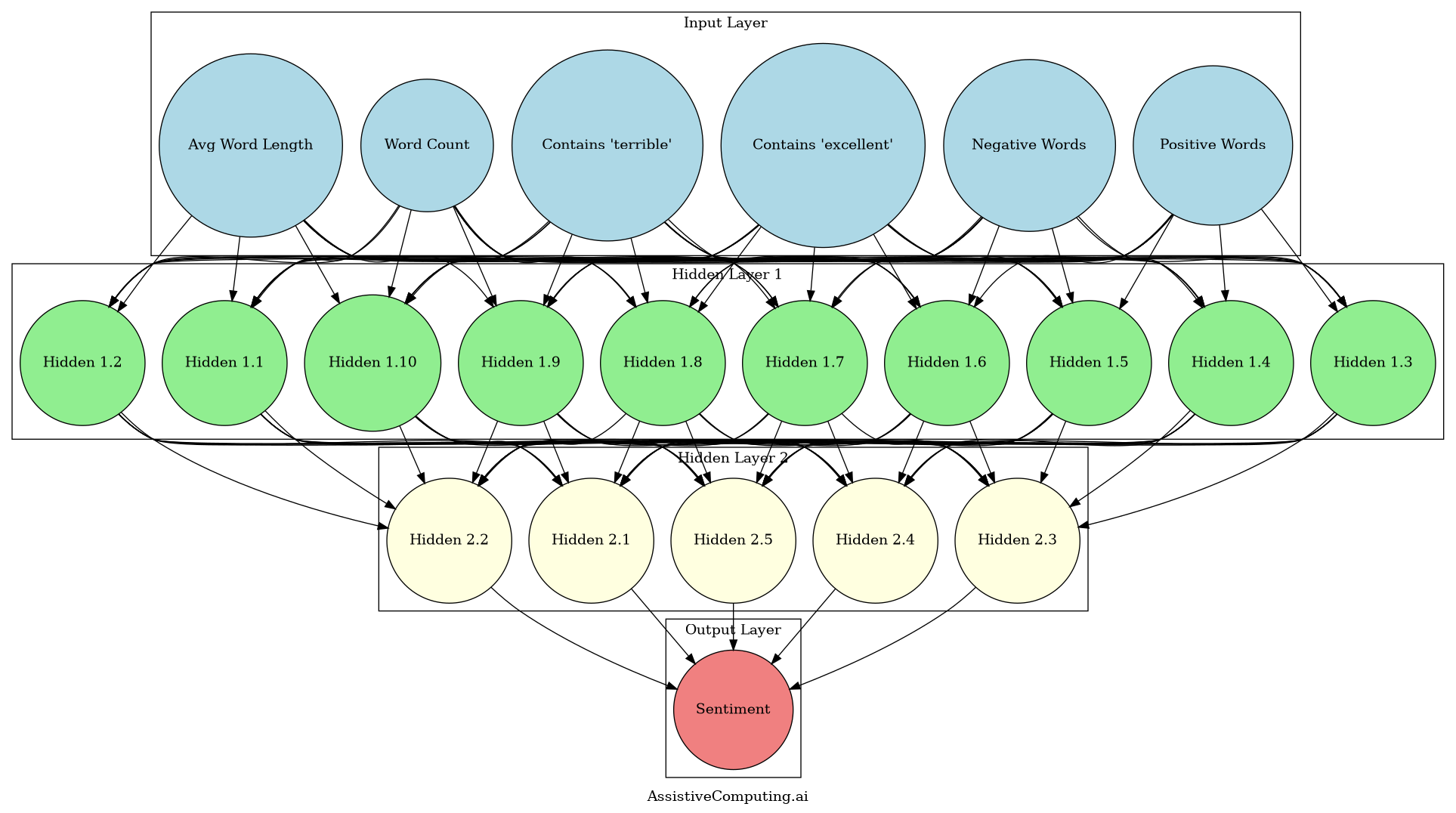
Figure 1: Sentiment Analysis Neural Network Structure
This diagram shows the architecture of our sentiment analysis neural network. The input layer (blue) consists of 6 nodes representing our features: Positive Words, Negative Words, Contains ‘excellent’, Contains ‘terrible’, Word Count, and Avg Word Length. These connect to the first hidden layer (green) with 10 nodes, which in turn connects to the second hidden layer (yellow) with 5 nodes. Finally, all nodes in the second hidden layer connect to the single output node (red) that predicts the sentiment. The lines between nodes represent the weighted connections that the network learns during training.
This visual representation helps us understand how the different layers interact and how information flows through the network from input to output.
How much data do I need?
To train this neural network effectively, we need to estimate the required amount of data.
Theoretical minimum
As a guideline, it is recommended to have at least 10 times the number of training examples as there are parameters in a neural network. This recommendation, based on empirical studies, ensures the model learns meaningful patterns without overfitting. While not an absolute rule, it provides a useful starting point for estimating data requirements.
The total number of parameters in the network can be calculated as follows:
- Input to Hidden Layer 1:
- Weights: \(6 \text{ input nodes} \times 10 \text{ hidden nodes} = 60 \text{ weights}\)
- Biases: 10 (one for each hidden node)
- Hidden Layer 1 to Hidden Layer 2:
- Weights: \(10 \text{ hidden nodes} \times 5 \text{ hidden nodes} = 50 \text{ weights}\)
- Biases: 5 (one for each hidden node)
- Hidden Layer 2 to Output Layer:
- Weights: \(5 \text{ hidden nodes} \times 1 \text{ output node} = 5 \text{ weights}\)
- Biases: 1 (for the output node)
Total parameters: \(60 + 10 + 50 + 5 + 5 + 1 = 131 \text{ parameters}\)
Using the guideline, we estimate:
\[131 \text{ parameters} \times 10 = 1,310 \text{ reviews}\]This theoretical minimum of approximately 1,310 reviews provides a baseline for training.
Overfitting
Overfitting occurs when a neural network learns the training data too well, capturing noise and specific patterns that do not generalize to new data. This results in excellent performance on the training set but poor performance on unseen data. Overfitting typically happens when the model is too complex relative to the amount of available training data.
Practical Considerations
While 1,310 reviews might be the minimum, practical considerations often necessitate more data to account for:
- Noise and Variability: Sentiment analysis involves understanding nuanced language, which requires more examples to capture variability.
- Generalization: Larger datasets help the model generalize better to new, unseen data.
- Overfitting: More data helps prevent overfitting, ensuring the model performs well on new data.
Recommended Dataset Size
For a more robust sentiment analysis model, it is advisable to aim for larger datasets:
- Minimum: 5,000 reviews
- Optimal: 10,000 to 50,000 reviews

Bill Hollingsworth
Educator, Software Developer, and Innovator in Assistive Technology